I’ve just finished another project here in Joensuu, Finland. This was done in course Speech Technology Workshop 2014. Our task was to classify speaker age and gender. We used this dataset Burkhardt, Felix et al. “A Database of Age and Gender Annotated Telephone Speech.” LREC 19 May. 2010. Basically we had 7 classes of speakers (child with no gender division, youth f/m, adult f/m , senior f/m). They recorded their voice using telephone. The average length of record is 2.58 seconds and we had ~35,000 training records and ~20,000 test records.
Implementation
We’ve written the script in Python and used Bob toolkit. You can find our code at github. You can see final report. We used Gaussians Mixture Models, MFCCs, VAD, you can read it all in final report or directly in the code. We tried GMM, without VAD, with Universal Background Model and MAP adaption, including first and second delta derivatives and raising number of gaussians for each GMM.
Results
Not good. We had only ~44% success rate of overall classification. Gender classification was good (~95%), it is easy task done years before. But age classification was really poor (~48%).
Here you can see our confusion matrix of one of experiments with nice chessboard pattern, that is caused by lame age recognition.
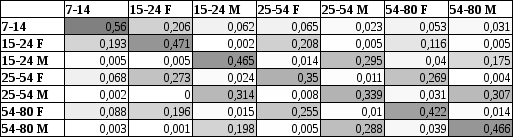
We think that this results are caused by length of records (only ~2.58) and by that class division, that was made because of marketing purposes and not with taking in account of actual changes of voice during lifetime.